

DeepSeek的阳谋:在《自然》杂志公布论文,到底赢得了什么?
画面中的立方体代表着电子神经元,也就是我们常说的“大模型参数”,每个神经元都在向着深层次方向探索。红色的线代表关键的核心信号,而白色的线则意味着发散的探索。最终,所有的探索都会变成电子神经元之间的链接,最终完成对问题答案的探索。
DeepSeek经历了几次爆火之后,已经成了连老妈都熟悉的大众词汇。这回登上《自然》杂志的封面,大家的第一反应就是:“遥遥领先”以及“厉害了我的国!”
不过别着急庆祝,如果你想知道DeepSeek为啥遥遥领先,以及领先在什么地方,那就把本文看完。全文大白话,包你一看看就懂。
在《自然》杂志的官方评论里,有一个词被反复强调了很多遍。这个词不是“性能强大”,也不是“技术突破”,而是听起来平平无奇的“同行评审”。
《自然》杂志说:目前所有主流的大模型都没有经过独立的同行评审,而 DeepSeek 填补了这项行业空白。

这就怪了。AI 领域日新月异,GPT 都更新到第 5 代了,同行评审就是让你把成果拿给行业专家看看,怎么还能轮到后起之秀的 DeepSeek 来打破空白呢?难道,过去这些年,全世界的 AI 巨头们,都是在王婆卖瓜的吗?
这个同行评审机制,就像是科学圈儿里的“质监局”。任何一项新的科学发现,想要获得公认,就必须把所有的实验方法、数据、推导过程,毫无保留地交给同行去匿名审查。

要知道,同行是冤家这话可不是白说的,这些同行专家可不想你轻松获得荣誉,他们恨不得你翻车。所以,同行评审往往是一个拿着显微镜挑刺的过程。实验设计不严谨啊,实验创新型不够啊,实验数据不完整啊……反正各种问题全能给你挑出来。
当然,挑刺归挑刺,但是科学家还是讲究科学精神的,真正过硬的研究,也会因为严格的同行评审而获得信任。
但是,人工智能大模型这个行业从一开始就被 ChatGPT-3 带了个坏头,ChatGPT-3 只开放了很少的一部分代码,公开了一些类似于产品说明书的所谓技术细节。从此以后,黑箱发布就成了大模型产品发布的“江湖规矩”。新的大模型产品看起来根本不像是一项科学研究,更像是一个产品发布会。大家通常只能看到一个惊艳的结果,至于核心的训练方法和数据细节,往往以商业机密为由秘不示人。
DeepSeek 这次做的,就是选择堂堂正正地接受科学界最严苛的质检。这就是《自然》杂志说 DeepSeek 填补了行业空白的原因。
当然,填补行业空白只能证明 DeepSeek 的担当和勇气,这与技术和创新没有关系。这篇论文让科学界真正兴奋的,是他们用另辟蹊径的方法和扎实的实验数据,狠狠打了其他大模型的脸。
之前科学家们一直以为,要想让一个 AI 模型变得更聪明,唯一的办法,就是把海量人类专家写好的解题步骤“喂”给 AI,让它去模仿学习。学得越多,能力也就越强。这与我们学校里推行的教育方式基本一致,我告诉你经典例题和标准答案,你给我背下来。这种方法叫做监督式微调(SFT)。
但 DeepSeek 的科学家们提出了一个大胆的假设:总是模仿人类的解题思路,会不会反而限制了 AI 的发展?就好像学生如果必须严格按照老师的思路学习,是不是就无法超越老师?有没有可能,让 AI 自己去发现规律,然后自学成才?
这个想法其实并不算石破天惊,但是绝对叛逆。因为如果允许学生自学,还允许他们发明老师都没用过的解题思路,那么,一旦学生成功解出老师也无法解答的问题,那么老师就必须承认,教学并不是学生成才的必经之路。
DeepSeek 的科学家决定豪赌一把。他们绕过了用人类范例教学的传统步骤,直接把一个名叫 DeepSeek-R1-Zero 的模型扔进了试炼场里。
这就像把一个没上学的孩子,直接扔进奥数赛场,没有基础知识,没有公式和技巧,只告诉他:“答对了有糖吃,答错了没有。你自己想办法吧。”
这种方法,就是论文里说到的“强化学习”,它的本质就是纯粹的激励。DeepSeek 的科学家们想看看,在巨大的难题压力和最纯粹的奖惩激励下,AI 的推理能力能否自发地涌现出来。
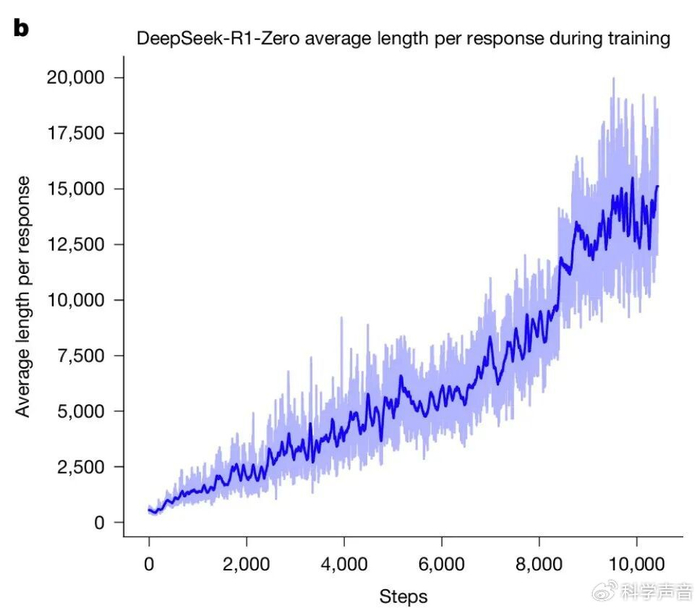
科学家发现,随着训练的进行,模型生成的回答文本长度在持续、稳定地暴涨。这说明,在没有任何外部指令的情况下,AI 自己领悟了一件事:那就是简单粗暴解决不了复杂问题,花更多的时间去推演和探索有助于获得正确答案。于是,它不再追求一口吃个胖子,而是自发地选择了深度思考这条路线。
在训练过程中,模型开始自发地使用一些代表反思的词汇,比如“等等”、“不对”、“我要检查一下”、“验证”、“好像有错”或者类似的话。
论文里给出了一个堪称神来之笔的案例。在解决一个数学问题时,模型先是按照一个思路进行推导,但写着写着,它突然停了下来,然后自己打出了一行字:

然后,它就真的像一个突然想通了什么的学生一样,推翻了之前的思路,开始一步一步地重新对问题进行评估,整个过程与那些突然发现了问题,然后从头开始检查的学生一模一样。
这个顿悟时刻,让见多识广的科学家们都感到兴奋。科学家在论文中写道:“DeepSeek 的顿悟时刻,也是我们的顿悟时刻,让我们见证了强化学习的强大力量”。
而且,这不是一个简单的个案。数据显示,在训练达到大约 8000 步之后,“wait”这个词的使用频率突然飙升,说明三思而后行已经成了它刻入骨髓的思维习惯。因为必须拿出正确答案才有糖吃。“对”比“快”重要得多。
最终,这个没有人类老师手把手教的大模型,靠着自己在试炼场里的摸爬滚打,自发地进化出了包括自我反思、过程验证、动态调整策略等一系列高级的推理模式。
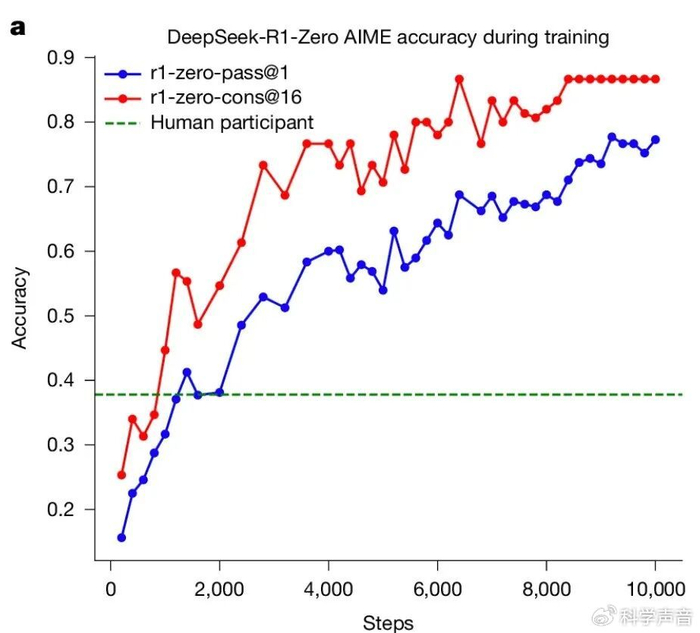
最终的结果是,在数学、编程等可验证的严肃推理任务上,它的表现全面超越了那些接受传统填鸭式教学的模型。在 AIME 数学竞赛基准测试上,它的最终成绩甚至远超人类参赛者的平均水平。这个没有老师全靠自学的孩子,向人类证明了自己的能力。
读到这里,你可能会产生一个非常自然的疑问:我们费了这么大劲,探索出了这么厉害的独门秘籍,为什么要把它公之于众?又是写论文,又是开源模型,这不是让竞争对手抄作业,自己吃亏吗?
从短期的、零和博弈的商业直觉来看,保密确实是最佳选择。而且,除了 DeepSeek 以外,就算是其他开源的大模型,也没有如此认真地接受同行评审。但是,从长期的、更宏大的发展视角看,开放和透明,恰恰是所有竞争对手都无法破解的阳谋。
第一,开放是建立信任的唯一途径。AI 正在成为社会的基础设施,一个不透明的黑箱,是无法得到国际社会的真正信任的。
DeepSeek 通过《自然》杂志的同行评审,等于是在向全世界宣告:我的能力是经得起最严格检验的,是可靠的。在一个人人都在谈论 AI 安全和 AI 伦理的时代,一个“可信”的标签,是花多少钱都买不来的无形资产。
第二,开放是加速自我进化的最佳策略。科学的发展史一再证明,闭门造车永远比不上开放社区的集体智慧。当 DeepSeek 把自己的方法和模型公开后,全世界成千上万的顶尖头脑都会成为它的免费测试员和外部智囊。
他们会发现你没注意到的漏洞,会提出你没想到的优化方向,甚至会基于你的工作,开发出让你也备受启发的新应用。这种来自全球社区的反馈和激荡,是任何一个封闭的公司靠内部力量都无法企及的,它会极大地加速自身的迭代速度。
第三deepseek,开放是吸引顶尖人才的终极引力场。顶尖的科学家和工程师,最看重的是什么?是解决世界级难题的机会和获得全球同行认可的声誉。一篇《自然》封面论文,就是向全球人才发出的最强招募令,它证明了这里是能够做出世界级工作的顶级平台。这种对人才的吸引力,远比保住一两个技术秘密的价值要大得多。
所以你看,开放和透明,看似吃亏,实则是在下一盘更大的棋。它赌的不是用户数或者会员费这些眼前得失,它通过建立信任、融入全球智慧网络、吸引顶尖人才,来赢得整个 AI 时代的长期竞争。
如果说,选择在《自然》上公开发表,是赢得了一种“安全可信”的科学信誉。那么,他们在论文中揭示的“AI 可以自学”的新规律,则赢得了对人工智能本质的认知优势。
DeepSeek 的科学家们用一场无可辩驳的漂亮实验,证明了 AI 的推理能力,不一定需要学习人类的固有知识,它们完全可以像人类一样,通过观察世界而独立发现规律。旧的规律如此,新的规律当然也没问题。
这个发现,极大地拓展了我们对人工智能潜力的想象。它把 AI 从一个只能模仿人类知识的学生,升级成了能独立发现新规律的科学家。
这事儿甚至可以直接扩展到教育界:一个孩子考上清北,学校、老师、家长都觉得是自己牛逼,其实你们都太自恋了,牛逼的是孩子自己。原文出处:DeepSeek的阳谋:在《自然》杂志公布论文,到底赢得了什么?,感谢原作者,侵权必删!

