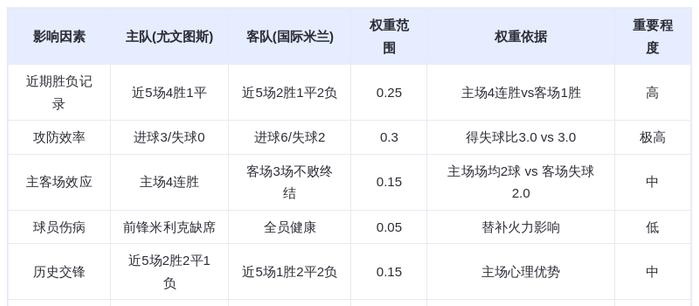
DeepSeek登上《Nature》封面,梁文锋打破质疑,给国人长脸了
Nature》上发表论文是所有科研人员的梦想,那么让自己的研究成果登上封面,就相当于赢得了科学界的“奥斯卡最佳影片”。
这本创刊于1869年的期刊,是全球科学界公认的“圣杯”,代表着最前沿、最重磅、最可能改变世界的发现。而封面,则是优中选优,只留给当期最耀眼的那颗星星。
而在这份长长的作者名单中,还有一位特别的成员——来自上海的高中生涂津豪。他曾在腾讯混元、DeepSeek实习,是开源项目Thinking-Claude的作者,也是2024阿里全球数赛AI挑战赛的冠军。
这中间的漫长时间,恰恰是这篇论文价值连城的关键所在——DeepSeek-R1经历了长达半年的、由八位外部独立专家参与的严苛同行评审过程。
这个过程的意义,远超论文本身。据《Nature》官方审稿人的描述,当今的AI行业,充斥着“令人印象深刻的发布会演示”、“不断刷新的排行榜分数”以及各种“未经证实的宣传和炒作”。
而DeepSeek选择了一条最艰难也最光荣的路:将自己的模型设计、方法论和局限性,毫无保留地交给全世界最顶尖的独立专家进行审视和“挑刺”。
正是这一勇敢的举动,创造了两个历史性的“第一”:全球第一个经过同行评审的主流大语言模型以及第一个登上《Nature》封面的中国大模型。
在此之前,几乎所有主流大模型都未经过独立的学术评审。《Nature》期刊自己也评论道,这个空白“终于被DeepSeek打破了”。
此次论文的补充材料中,首次公开了R1模型仅用29.4万美元(约合人民币209万元)的训练成本——使用H800芯片从V3-base版本训练至R1,成本仅为行业平均水平的1/10。
相比之下,诸如ChatGPT、谷歌Gemini等竞争对手动辄需要数千万甚至上亿美元的投入,DeepSeek的成本控制堪称奇迹。
与1月份未经评审的初版相比,发表在《Nature》上的新版论文包含了大量的补充材料,其中不仅披露了海量技术细节,还正面回应了模型发布之初的核心争议。
先说这篇论文最大的亮点,就是证明了仅通过纯强化学习(Pure Reinforcement Learning, RL),就能显著激发大模型的推理能力,而无需大量人工标注的“标准答案”。
传统的训练方法,比如监督微调(SFT),就像是给学生一本习题册,上面既有题目也有详细的解题步骤和答案。学生要做的,是学习并模仿这些“标准解法”。
它更像是把学生关在一个只有题目和草稿纸的房间里,不提供任何解题范例。学生可以自由地用任何方法尝试解题,最后只需要把答案提交。
在这种模式下deepseek,模型为了获得更多奖励,必须自己去“悟”,去探索什么样的思考路径、什么样的解题策略,才能最终导向正确的答案。
为了提升效率,团队还采用了名为“群体相对策略优化”(GRPO)的算法,省去了一个庞大的“裁判”模型,从而大幅降低了训练成本。
最令人惊奇的是,通过这种“粗放”的训练,模型(特指其前身DeepSeek-R1-Zero)竟然自发地涌现出了多种类似人类的、复杂且高级的推理行为,而这些都是研究人员从未明确教过它的。
研究人员甚至观察到了模型的“顿悟时刻”(Aha moment),在它的“内心独白”(推理过程)中,会突然出现“等等”(wait)这样的词,然后停下来重新评估自己最初的思路,修正错误。
一方面,面对复杂难题,模型会不惜花费成百上千个“词元”(token)来进行深度思考和推理,展现出惊人的专注和严谨;
另一方面,模型还自己学会了“偷懒”,对简单问题用较少的步骤快速解决,对复杂问题则投入更多的计算资源进行深度思考,实现了计算力的智能分配。
今年1月模型刚发布时,曾有媒体报道称OpenAI的研究人员认为DeepSeek涉嫌使用“蒸馏”技术——即用OpenAI模型生成的数据来训练自己的模型,从而用更低的成本“抄近道”。
在与审稿人的沟通中,团队明确指出,R1模型的核心推理能力,是通过其独创的纯强化学习过程独立训练出来的,并没有学习或复制任何由OpenAI模型生成的推理范例。
当然,团队也坦诚地承认,其基础模型是在海量的互联网数据上训练的,其中自然不可避免地吸收到一些其他AI生成的内容。
俄亥俄州立大学AI研究员Huan Sun表示,这个解释“与我们在任何出版物中看到的一样令人信服”。
《Nature》审稿人Lewis Tunstall强调,将主流大模型提交同行评审是“一个值得欢迎的先例”,因为这为评估和管理AI风险提供了开放的基础。
作为全球最顶级的科学权威机构,Nature正在借助DeepSeek的案例,向OpenAI、Google、Anthropic等巨头发出呼吁:请把你们的模型也拿到阳光下,接受科学共同体的检验。
他们选择了“开放权重”(Open-weight)的模式,将模型的核心参数公之于众,任何人都可以下载、研究和改进他们的工作。
这一举动引爆了全球开发者社区,DeepSeek-R1迅速成为AI社区平台Hugging Face上同类模型中下载量最高的模型,累计下载超过1090万次。
此外,团队还贴心地发布了多个“蒸馏”后的小尺寸模型,让那些没有海量计算资源的研究者和开发者也能用上先进的推理能力。
在长达64页的同行评审报告中,8位审稿人共提出上百条具体意见,其中提到了DeepSeek数据细节仍不够透明,奖励机制尚待优化以及安全与伦理审查尚属起步阶段等问题。
例如有审稿人要求DeepSeek在论文中附上SFT和RL数据的链接,而不仅仅是提供数据样本。
据彭博社消息,DeepSeek正在秘密研发一款具备自我进化能力的Agent。这款产品无需复杂指令,能自主学习并执行多步骤任务,还可从历史操作中迭代优化。
如果说《Nature》上的这篇论文证明了模型可以在虚拟的数学世界里“自我进化”出推理能力,那么这款Agent的目标,可能就会让模型在更广阔的数字世界里,通过与环境的真实交互,“自我进化”出解决实际问题的行动能力。
梁文锋和他的团队,真实目的应该是创造出能够自主学习、不断成长的AI新物种,从而彻底改变人机协作的范式。原文出处:DeepSeek登上《Nature》封面,梁文锋打破质疑,给国人长脸了,感谢原作者,侵权必删!